В одном крупном университете на Юге России я разрабатываю программную платформу автоматизированного построения графа социальной сети при помощи обработки интернет страниц социальных сетей. В данной статье я расскажу, как мы обрабатывали данные, собранные из Живого журнала (Livejournal.com).
Прошел почти год, я думаю, будет интересно узнать, как система применялась для автоматизированного сбора данных в период избирательной кампании в Государственную думу в 2011 году.
Для генерации таблицы упоминаний обработка страниц социальных сетей и блогосферы (парсинг) реализуется с применением модуля Feeds для CMF Drupal с плагином SimpleHTMLDOMparser. В процессе парсинга система обращается к странице с информацией в Интернет и производит выборку данных из DOM дерева HTML в соответствии с набором тегов и каскадной таблицей стилей.
Рассмотрим конфигурацию модуля для импорта в систему комментариев пользователей. Система разработана таким образом, что позволяет разделять собираемую информацию на элементарные части, каждая из которых представляет собой отдельное поле в базе данных. Импорт производится гранулярно, что впоследствии дает возможность гибко фильтровать результаты. В набор собираемых данных (см. рис. 1) входят следующие экстракторы (Extractions):
заголовок комментария;
автор комментария – никнейм пользователя в сети или блоге;
автор журнала – запись, к которой относится комментарий;
комментарий – собственно текст;
ссылка на комментарий;
журнал комментатора;
журнал автора поста;
дата комментирования – актуальная дата размещения комментария в сети.
Рис. 1. – Настройки экспорта данных в модуле Feeds
Поиск данных производится иерархически:
В частности, для поля «Автор комментария» необходимо установить паттерн «ul[class='info b-hlist b-hlist-middot'] li a» с атрибутом «plaintext». Такой паттерн обеспечивает погружение в дерево DOM HTML и экспортирует все элементы, которые находятся в ненумерованном списке «ul» с классом «info b-hlist b-hlist-middot» и обернуты тегом «a» (см. рис. 2).
Рис. 2. – Настройка паттерна и атрибутов поля «Автор комментария» в модуле Feeds
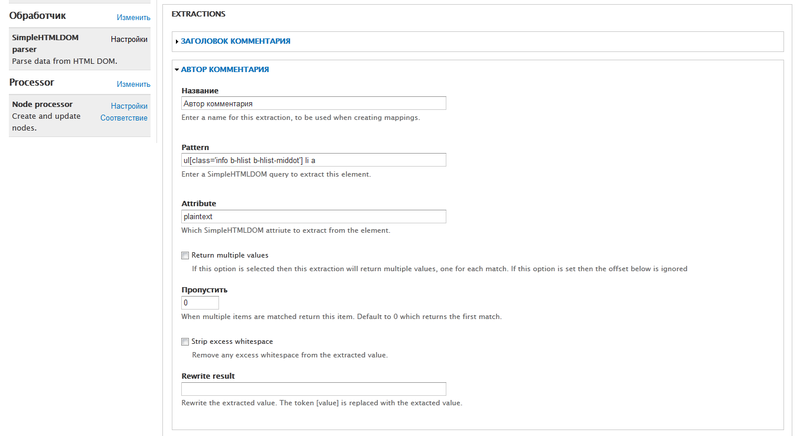
Каждый экспортируемый элемент в системе соответствует предустановленным полям типа материала Feed item (экземпляр фида). Таблица соответствия представлена на рис. 3.
Рис. 3. – Настройка паттерна и атрибутов поля «Автор комментария» в модуле Feeds
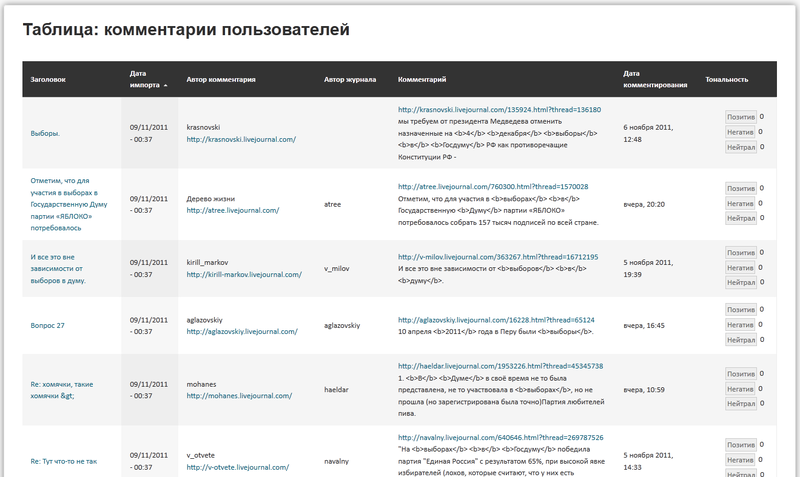
После настройки всех необходимых параметров система начинает парсинг по выбранным ключевым словам. В результате в системе будет сформирована таблица с набором данных о комментариях, представленная на рис. 4: заголовок комментария, дата его импорта в систему, автор комментария, автор блога, к которому относится комментарий, текст комментария, дата его публикации в сети Интернет, тональность (позитив, негатив, нейтрал), определяемая пользователем системы.
Рис. 4. – таблица с данными комментариев
Для дальнейшего анализа графа производится экспорт сформированной таблицы в один из поддерживаемых форматов. Для экспорта следует воспользоваться кнопкой XLS, находящейся под таблицей, рис. 5.
Рис. 5. – кнопки экспорта таблицы
В процессе экспорта можно наблюдать за его прогрессом: отображается время, которое необходимо системе для формирования файла и процент выполнения, рис. 6.
Рис. 6. – процесс экспорта данных
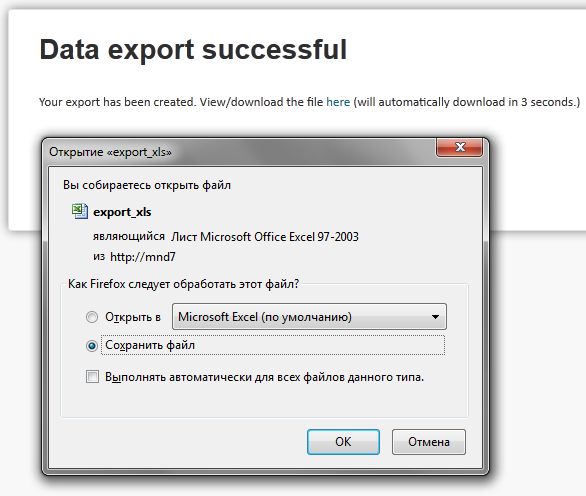
Результат экспорта – файл, который следует сохранить для дальнейшего анализа графа, рис. 7.
Рис. 7. – результат экспорта
Реализации технологии мониторинга агитационных действий с помощью разработанной модели и с использованием описанного алгоритма будут полезны на разных этапах мониторинга социальных сетей и избирательного процесса – как во время избирательных кампаний, так и в периоды между ними.
Также возможно применение системы сбора данных и формирования графа в любых сферах деятельности, где структура может быть представлена в виде графа с четко выраженными узлами и связям между ними. Вы, конечно, хотите на граф посмотреть?) Это первая статья. В следующей я расскажу о визуализации и анализе получившегося графа и тех выводах, которые мы сделали перед известными событиями прошлого декабря.
 АДМИНКА
АДМИНКА НАВИГАЦИЯ
НАВИГАЦИЯ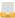 СВЯЗЬ С НАМИ
СВЯЗЬ С НАМИ РАДИО
РАДИО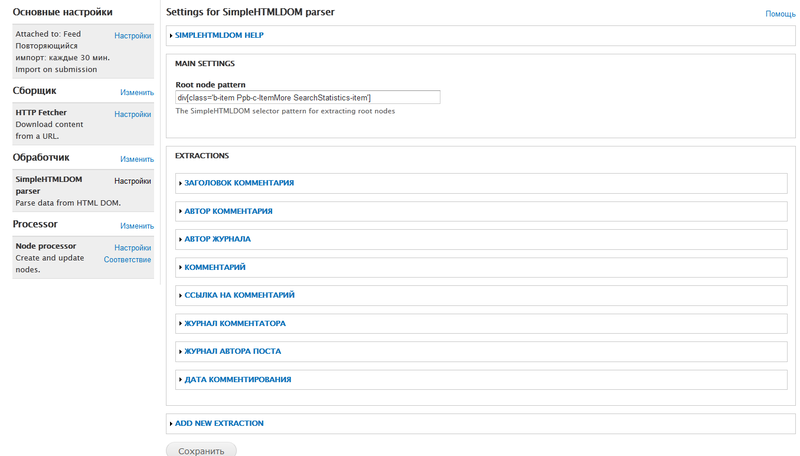

 ЛУЧШИЕ ЧАТЫ
ЛУЧШИЕ ЧАТЫ
 СЧЁТЧИКИ
СЧЁТЧИКИ