 АДМИНКА
АДМИНКА НАВИГАЦИЯ
НАВИГАЦИЯ СВЯЗЬ С НАМИ
СВЯЗЬ С НАМИ РАДИО
РАДИО«Data Mining: Первичная обработка данных при помощи СУБД. Часть 1»
Раздел: Социальные сети
О чем статьяВ задачах исследования больших объемов данных есть множество тонкостей и подводных камней. Особенно для тех, кто только начинает исследовать скрытые зависимости и внутренние связи внутри массивов информации. Если человек делает это самостоятельно, то дополнительной трудностью становится выбор примеров, на которых можно учиться и поиск сообщества для обмена мнениями и оценки своих успехов. Пример не должен быть слишком сложным, но в тоже время должен покрывать основные проблемы, возникающие при решении задач приближенных к реальности, так чтобы задача не воспринималась примерно вот так:  С этой точки зрения, очень интересным будет ресурс Kaggle[1], который превращает исследование данных в спорт. Там проводят соревнования по анализу данных. Некоторые соревнования — с обучающими материалами и предназначены для начинающих. Вот именно обучению анализу данных, на примере решения одной из обучающих задач, и будет посвящён цикл статей. Первая статья будет о подготовке данных и использованию СУБД для этой цели. Собственно, о том, как и с чего начать. Предполагается что читатель понимает SQL. Задача: «Титаник: Машинное обучение на катастрофах.»Одно из двух соревнований для начинающих — «Титаник»[2]. Перевод задания: «Гибель Титаника это одно из наиболее бесславных кораблекрушений в истории. 15 апреля 1912 года, во время своего первого рейса, Титаник затонул после столкновения с айсбергом, погубив 1502 из 2224 человек пассажиров и команды. Эта сенсционная трагедия шокировала международное сообщество и привела к улучшению требований правил техники безопасности на судах. Одной из причин того, что кораблекрушение повлекло такие жертвы, стала нехватка спасательных шлюпок для пассажиров и команды. Также был элемент счастливой случайности, влияющий на спасение от утопления. Также, некоторые группы людей имели больше шансов выжить чем другие, такие как женщины, дети и высший класс. В этом соревновании мы предложим вам завершить анализ того, какие типы людей скорее всего спасутся. В частности, мы попросим вас применить средства машинного обучения для определения того, какие пассажиры спасутся в этой трагедии.» ДанныеДля соревнования дано два файла: train.csv и test.csv. Данные в текстовом виде разделенные запятыми. Одна строка — одна запись о пассажире. Некоторые даные для записи могут быть неизвестны и пропущены. ОПИСАНИЕ ПЕРЕМЕННЫХ:
Примечание: Pclass является показателем социально-экономического статуса (SES) 1st ~ Upper; 2nd ~ Middle; 3rd ~ Lower Возраст в годах; Дробный, если возраст меньше единицы(1) Если возраст оценочный — то он в форме xx.5 Следующие определения используются для sibsp и parch. Братья(Сестры): Брат, Сестра, Сводный брат, или Сводная сестра среди пассажиров Титаника Супруги: Муж или Жена среди пассажиров Титаника (Любовницы и Женихи игнорируются) Родители: Мать или Отец среди пассажиров Титаника. Дети: Сын, Дочь, Пасынок или Падчерица среди пассажиров Титаника. Другие члены семьи исключены, включая кузенов, кузин, дядь, тетушек, невесток, зятей Дети, путешествующие с нянями имели parch=0. Точно также путешествующие с близкими друзьями, соседями, не учитываются в родственных отношениях parch. Эта задача, как видим, является хорошо структурированной и поля практически определены. Собственно, первый этап заключается в том, чтобы подать данные для машинного обучения. Вопросы выбора и переопределения полей, разбиения, слияния, классификации — зависят от подачи данных. По большому счету вопрос упирается в кодирование и нормализацию. Кодирование качественных признаков(существует несколько подходов) и предварительную обработку данных перед применением методов машинного обучения.Данная задача не sсодержит действительно большого объема данных. Но большинство задач(например Herritage Health Pr., Yandex интернет-математика ) не такие структурированные и приходиться оперировать миллионами записей. Делать это удобней с использованием СУБД. Я выбрал СУБД PostgreSQL. Весь SQL код писался под эту СУБД, но с небольшими изменениями подойдет и для MySQL, Oracle и MS SQL сервер. Загружаем данныеСкачиваем два файла — train.csv и test.csv. Создаем таблицы для хранения данных: В результате получаем две таблицы: с тренировочными и тестовыми данными. В этом случае не было ошибок загрузки данных. Т.е. все данные соответствовали тем типам, которые мы определили. Если же ошибки появляются — тогда есть два пути: сначала исправить и регулярными выражениями и редактором вроде sed(либо командой на основе perl -e) или сначала все загрузить в виде текстовых данных, и исправлять регулярными выражениямии запросами средствами СУБД. Добавим первичный ключ: Исследование данныхТаблицы СУБД это всего-навсего средство. Средство помогающее удобнее изучать и преобразовывать данные. С самого начала удобно разделить поля записи про каждого пассажира на числовые и текстовые — по типу данных. Для применения машинных алгоритмов обучения, все равно прийдется все преобразовать к числовому представлению. И от того, насколько адекватно мы это сделаем, очень сильно зависит качество работы методов, которые мы выберем. Числовые данные: survived, pclass, age, sibsp, parch, fare Текстовые данные: name, sex, ticket, cabin, embarked Начнем с данных, которые представлены в текстовом виде. Фактически, это проблема кодирования информации. И тут не обязательно самый простой подход будет самым правильным. Например, если отвлечься от этого примера, и представить, что у нас есть поле, которое определяет должность:
Вполне логично кодировать их таким образом:
Т.е. мы таким образом попытались вписать такой вот элемент реальности как должности, в математическое представление. Это один(простейший) вариант подачи такой информации. Это при условии, что «расстояние» между должностями(что не соответствует реальности) считаем одинаковым. Т.е. тут возникает вопрос, а что такое «расстояние между должностями»? Важность? Объем полномочий? Объем ответствености? Распространенность? Место в иерархии? Или количество работников в такой должности на предприятии? Масса вопросов, на которые для задачи оторванной от реальности и не будет ответа. А в реальности ответы есть. И есть методы, которые помогают приблизить математическое представление к реальности. Но это тема для отдельной и сложной статьи, а пока, примем, что мы будем стараться кодировать данные в диапазоне от 0 до 1(Код 2). Итак, для данных которые можно сравнить, есть хоть какое-то объяснение почему мы именно так, с определением меньшего и большего кодировали даные. Ведь числа несут количественную информацию! Что-то больше, а что-то меньше! А если у нас в качестве описательной информации «имя». Имеем ли мы право кодировать Данные например вот так:
Вроде бы и можем мы так кодировать, но получается, что мы добавляем к данным составляющую, которой нет — сравнение имен(числа: больше-меньше) по неизвестному признаку. Логичней было бы подать данные несколько иначе(Ещё это называют bag-of-words):
И вот сколько будет имен — столько будет и полей. И значения: 0 или 1. Недостаток налицо — а если у нас будет миллион разных имен? Что делать? В нашей простой задаче такой беды нет, но отвечу — это довольно динамично растущая отрасль компьютерных наук и математики — сжатие входных данных. Одно из ключевых слов — «sparse matrix». Ещё — «autoencoder», «Vowpal Wabbit»[3], «feature hashing». Опять таки — это тема для статьи. Кроме того, на хабре мелькали материалы по этой теме. Но для нашей задачи, мы пока отвлечемся от этой проблемы. И вернемся к вопросу: А имеет ли первое представление право на жизнь? Ответ сильно зависит от того, а можем ли мы пренебречь добавленной нами составляющей о ранжировании «неизвестного признака по которому мы сравнивали имена». Очень часто приходиться пренебрегать — когда другой возможности нет. А если поставить вместо имен например число-буквенные номера билетов(что уже ближе к нашей задаче). С билетами проще — есть серия и есть номер. Номер можем оставить так как есть. Возможно он определяет место посадки, и соответственно дальность расположения от входа и т.п. А вот кодирование серии — уже сложнее. Прежде всего нужно ответить на вопрос: А может ли одно значение в реальности быть представлено в виде разных строк в даных? Ответ однозначный — может. Т.е. нужно это проверить. Самый простой вариант — опечатка. Лишняя точка, запятая, пробел или тире. Наличие таких данных уже влечет искажения, и модель кторая построена на «испорченных» сведениях не покажет хорошего результата (только если это не делалось контролируемо для улучшения свойства обобщения модели). Для начала отделим номер билета от серии(типа, марки и т.п.). Для этого просмотрим данные, предварительно отсортировав по названию. Выделим группы данных:
Далее поступим таким образом: создадим таблицу, где серия выделена в отдельное поле. Там где нет серии — пока поставим пустое значение. Для этого воспользуемся запросом: где '^\s*?(.*?)\s*?(\d*?)$' — регулярное выражение, позволяющее выделить части в поле билет — серию и номер в массив. Номера оставим так как они есть, можно проверить регулярным выражением на наличие нецифровых символов. При помощи подобного регулярного выражения. Проблема двойниковЕсли один и тот же объект реальности именуется по разному — получаем проблему двойников. Остановимся отлько лишь на одном аспекте обнаружения двойников: Опечатки в наименовании. Учитывая, что объем наших данных небольшой, и подлежит простому просматриванию, поступим таким образом — выведем все уникальные значения поля из таблицы. Запрос: А вот результат, где я отметил предположительно одинаковые значения, которые обозначены разными строками. 45 записей. 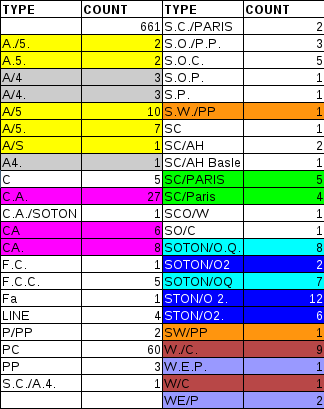 Довольно много совпадений. Если вникнуть в задачу глубже и узнать по какому принципу маркировались билеты — можно еще сократить количество наименований. Но, одним из условий задачи было не использовать дополнительных сведений по этой широкоизвестной трагедии. Потому остановимся только на этом. Запросы для изменения данных выглядят так: Теперь записей 30. В более сложных задачах, обработка существено отличается. Особенно, если просмотреть все не представляется возможным. Тогда можно воспользоваться функцией Левенштейна — это позволит найти близкие по написанию слова. Можна ее немного подправить и сделать слова которые отличаются только знаками препинания еще ближе. Опять-же возвращаемся к понятию меры и метрики — а что понимать под растоянием между словами? Символы которые более похожи по внешнему виду B и 8? Или те которые звучат похоже? В принципе, таким нехитрым способом нужно пройтись по всем символьным полям в тренировочной и тестовой таблицах. Ещё, как улучшение можно отметить объединение данных по столбцам из этих таблиц перед поиском двойников. О распределенности. На этом этапе работа по обработке данных не требует специальных знаний и может быть легко распаралеллена между некоторым числом исполнителей. Вот, например, на этом этапе, команда очень сильно обойдет соперника-одиночку. Пост получился довольно объемным, потому продолжение — в следующей части. Ссылки: 1. www.kaggle.com 2. www.kaggle.com/c/titanic-gettingStarted 3. http://hunch.net/~vw/ Обновление: Часть вторая: habrahabr.ru/post/165281/ Часть третья: habrahabr.ru/post/165283/ |
 ЛУЧШИЕ ЧАТЫ
ЛУЧШИЕ ЧАТЫ
 СЧЁТЧИКИ
СЧЁТЧИКИ