 АДМИНКА
АДМИНКА НАВИГАЦИЯ
НАВИГАЦИЯ СВЯЗЬ С НАМИ
СВЯЗЬ С НАМИ РАДИО
РАДИО«Какая часть веба заархивирована»
Раздел: Социальные сети
 Машина времени Internet Archive — самый большой и известный архив, который сохраняет веб-страницы с 1995 года. Кроме него существует с десяток других сервисов, которые тоже архивируют веб: это индексы поисковых систем и узкоспециализированные архивы вроде Archive-It, UK Web Archive, Web Cite, ArchiefWeb, Diigo и др. Интересно узнать, как много веб-страниц попадает в эти архивы, относительно общего числа документов в интернете? Известно, что база Internet Archive за 2011 год содержит более 2,7 миллиарда URI, многие из них в нескольких копиях, сделанный в разные моменты времени. Например, главную страницу Хабра «сфотографировали» уже 518 раз, начиная с 3 июля 2006 года. Известно также и то, что база ссылок Google пять лет назад перешагнула отметку в триллион уникальных URL, хотя многие документы там дублируются. Компания Google не в силах проанализировать все URL, так что компания решила считать количество документов в интернете бесконечным. В качестве примера «бесконечности веб-страниц» Google приводит веб-приложение календарь. Нет смысла скачивать и индексировать все его страницы на миллионы лет вперёд, ведь каждая из страниц генерируется по запросу. Тем не менее, учёным интересно хотя бы примерно узнать, какая часть веба заархивирована и сохранена для потомков. До настоящего момента никто не мог ответить на этот вопрос. Специалисты из Old Dominion University в Норфолке провели исследование и получили приблизительную оценку. Для обработки данных они использовали HTTP-фреймворк Memento, который оперирует следующими понятиями:
Соответственно, у каждого URI-R может быть ноль или больше состояний URI-M. С ноября 2010 года по январь 2011 года продолжался эксперимент по определению доли публично доступных страниц, которые попадают в архивы. Поскольку количество URI в интернете бесконечно (см. выше), то нужно было найти приемлемую выборку, которая репрезентативна для всего веба. Здесь учёные использовали комбинацию из нескольких подходов:
По практическим причинам, размер каждой выборки ограничили тысячей адресов. Результаты анализа показаны в сводной таблице для каждой из четырёх выборок. 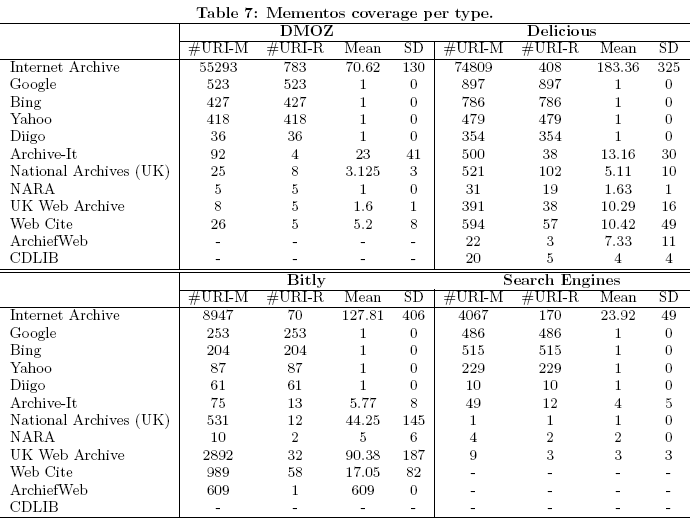 Исследование показало, что от 35% до 90% всех URI в интернете имеют хотя бы одну копию в архиве. От 17% до 49% URI имеют от 2 до 5 копий. От 1% до 8% URI «сфотографированы» 6-10 раз, а от 8% до 63% URI — 10 и более раз. С относительной уверенностью можно сказать, что не менее 31,3% всех URI архивируются раз в месяц или чаще. Как минимум для 35% всех страниц в архивах есть хотя бы одна копия. Естественно, вышеуказанные цифры не относятся к так называемой Глубокой сети (Deep Web), к которой принято относить динамически генерируемые страницы от БД, запароленные справочники, социальные сети, платные архивы газет и журналов, флэш-сайты, цифровые книги и прочие ресурсы, которые спрятаны за файрволом, в закрытом доступе и/или недоступны для индексирования поисковыми системами. По некоторым оценкам, Глубокая сеть может быть на несколько порядков больше по размеру, чем поверхностный слой. |
 ЛУЧШИЕ ЧАТЫ
ЛУЧШИЕ ЧАТЫ
 СЧЁТЧИКИ
СЧЁТЧИКИ