Я являюсь ярым фанатом геосоциальных сервисов. Они позволяют наглядно увидеть физическую реализацию социального пространства. Это то, о чем писал Бурдьё, но что для него было доступно лишь в виде мысленного конструкта. Foursquare вообще является моей безответной любовью. Но об этом как-нибудь в следующий раз, а сегодня поговорим о Twitter.
Незадолго до конца предыдущего, 2012-го, года мне захотелось увидеть, как выглядит «волна» новогодних твитов-поздравлений. Посмотреть, как она проходит через часовые пояса. Сказано — сделано. Использованные инструменты: R, Python и ffmpeg.
Сбор данных
Пока супруга занялась праздничными приготовлениями и не вспомнила про меня, с помощью python и tweetstream делаем примитивный парсер твит-потока statuses/filter.
import tweetstream
stream = tweetstream.FilterStream('TWITTER_LOGIN', 'TWITTER_PASSWORD', track = keywords_list)
for tweet in stream:
if tweet['coordinates']:
# Декодируем время создания твита в date-time объект
# (в API Twitter встречаются два возможных варианта написания)
try:
timestamp = datetime.datetime.strptime(tweet['created_at'], '%Y-%m-%d %H:%M:%S')
except ValueError:
timestamp = datetime.datetime.strptime(tweet['created_at'][4:-10]+tweet['created_at'][-4:], '%b %d %H:%M:%S %Y')
# Прибавляем 4 часа - "переводим" время на московское
timestamp += datetime.timedelta(hours=4)
# Сохраняем время создания в виде строки
timestamp = datetime.datetime.strftime(timestamp, '%Y-%m-%d %H:%M:%S')
# Пишем все в БД
cursor.execute('INSERT INTO tweets(link, latitude, longitude, date) VALUES ("http://www.twitter.com/{0}/status/{1}", "{2}", "{3}", "{4}")'.format(
tweet['user']['screen_name'],
tweet['id'],
str(tweet['coordinates']['coordinates'][0]),
str(tweet['coordinates']['coordinates'][1]),
str(tweet['created_at'])
))
db.commit()
keywords_list — Список ключевых слов, хеш-тегов и фраз, относящихся к поздравлению с Новым годом. Не забываем, что данный вызов API не учитывает морфологию, так что в ключевые слова надо постараться внести как можно больше релевантных словоформ. Мой список:
#сновымгодом,
#СНовымГодом2013,
#НГ2013,
#СНаступающим2013,
#НовыйГОД,
#СНаступающимНовымГодом,
#НОВОГОДНИЙтвит,
с новым годом,
с наступающим,
с новым 2013,
с годом змеи,
с наступающим годом змеи,
Нового Года,
новом году.
Все, супруга обратила внимание на лишние рабочие руки, так что запускаем парсер и спешим на помощь. Напоследок вносим свою лепту в «увеличение энтропии»:
Обзор полученных данных
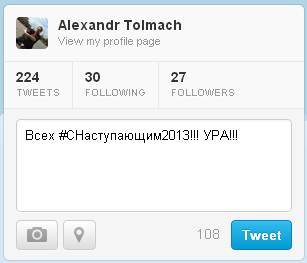
Ночь с пятницы на понедельник первые дни нового года пролетели незаметно. Праздник прошел, парсер можно выключать и смотреть на «улов». Всего набралось ~10 тыс. твитов. Геометки в Twitter не пользуются популярностью. Для мобильности я скинул дамп в .csv таблицу вида «ссылка — широта — долгота — временная метка». Грузим таблицу в R:
Переводим временные метки в соответствующий формат, округляем широты и долготы — будем смотреть твиттер-активность по сетке в одну десятую градуса. Последнее преобразование долгот необходимо для дальнейшей визуализации, чтобы не потерять сообщения с Чукотки.
Теперь подгружаем ggplot2 и смотрим распределение по времени:
library('ggplot2')
p <- ggplot()
p <- p + geom_histogram(aes(x=twits$Timestamp, fill = ..count..), binwidth = 3600)
p <- p + ylab('Количество') + xlab('Время (по часам)')
p <- p + theme(legend.position = 'none')
p <- p + ggtitle(expression('Распределение "новогодних" твитов'))
p
Выглядит все примерно так, как и ожидалось, что приятно радует. Можем продолжать.
Отрисовка карты
Ggplot2 предлагает богатый набор инструментов для быстрого построения информативных и симпатичных графиков. Полная документация с примерами: ggplot docs.
Для отрисовки карты будем использовать функцию geom_polygon, позволяющую рисовать полигоны по заданным координатам. Контуры стран будут браться из библиотеки maps. За основу был взят вариант отрисовки, описанный в заметке «How to draw good looking maps in R». Незначительно видоизменяем описанный вариант, подгоняя его под собственные нужды и «представления о прекрасном»:
# Грузим все данные
# countries - вектор с названиями стран, которые надо отрисовывать
library('maps')
full_map <- map_data('world')
table(full_map$region)
need.map <- subset(full_map, region %in% countries & long>-25 & long<190 & lat>25)
# Рисуем контуры
p <- ggplot()
p <- p + geom_polygon(aes(x=need.map$long, y=need.map$lat, group = need.map$group), colour='white', fill='grey20', alpha=.5)
# Рисуем "точки" отдельных крупных городов для "оживления пейзажа"
# cities - это dataframe вида "название города - широта - долгота"
p <- p + geom_point(aes(cities$Long, cities$Lat), colour='skyblue', size=1.5)
# Убираем подписи к осям, легенду, фиксируем размер поля для вывода, добавляем заголовок
p <- p + theme(axis.line=element_blank(),axis.text.x=element_blank(),
axis.text.y=element_blank(),axis.ticks=element_blank(),
axis.title.x=element_blank(),
axis.title.y=element_blank(),
legend.position = 'none',
text=element_text(family='mono', size=20, face='bold', colour='dodgerblue3')
)
p <- p + scale_x_continuous(limits = c(-15, 190))
p <- p + scale_y_continuous(limits = c(30, 82))
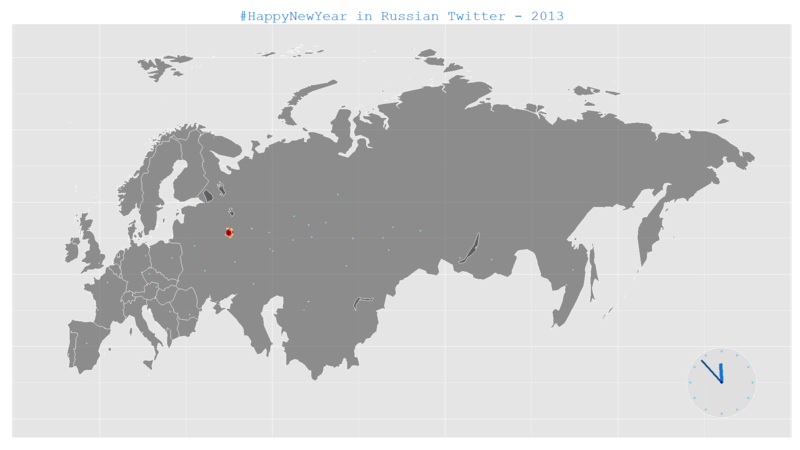
p <- p + ggtitle(expression('#HappyNewYear in Russian Twitter - 2013'))
Картинку хочется как-то оживить и добавить информативности. Поместим в кадр часы. Вот интересный вариант с часами: Create an animated clock in R with ggplot2 (and ffmpeg). Но там используется полярная система координат, что нам не подходит, т.к. потребует лишних телодвижений в виде создания подграфика. Придется делать свой «велосипед». Берем функцию для расчета координат окружности по центру и диаметру (подсмотрено здесь):
draw.circle <- function(center,diameter=1, npoints = 100){
r = diameter / 2
tt <- seq(0,2*pi,length.out = npoints)
xx <- center[1] + r * cos(tt)
yy <- center[2] + r * sin(tt) * roundcoef
return(data.frame(x = xx, y = yy))
}
Теперь считаем точки для трех окружностей: белый фон-задник, серый «верхний» фон и 12 точек на окружности для часовых засечек:
Рисуем часы (функции geom_polygon, geom_segment, geom_point):
# Три окружности: фон и часовые засечки
p <- p + geom_polygon(aes(x=circdat$x,y=circdat$y), colour='grey100', fill='grey100', alpha = .5)
p <- p + geom_polygon(aes(x=circdat2$x,y=circdat2$y), colour='grey80', fill='grey80', alpha = .5)
p <- p + geom_point(aes(circdat3$x, circdat3$y), colour='skyblue')
# Часовая стрелка, минутная, "гвоздик" оси стрелок
p <- p + geom_segment(aes(x=clock.center[1], y=clock.center[2], xend=hour.x, yend=hour.y), size=3, colour='dodgerblue3')
p <- p + geom_segment(aes(x=clock.center[1], y=clock.center[2], xend=minute.x, yend=minute.y), size=1.5, colour='dodgerblue4')
p <- p + geom_point(aes(clock.center[1], clock.center[2]), colour='blue4')
Вот что получилось (на карте еще и тестовые данные по «активности», но только в Москве и окрестностям):
Прорисовываем кадры
Исходные данные — таблица с координатами и временем публикации твита. На выходе мы хотим получить набор кадров. Сделаем так: будем в настройках задавать время 1-го кадра, время последнего кадра и временную разницу между соседними кадрами. Общее количество кадров будет рассчитываться в R. Далее — цикл от 1 до последнего кадра. В каждом кадре будет вычисляться «текущее» время. Далее — из исходной таблицы будем отбирать твиты, попадающие в требуемый временной интервал (30 минут до «текущего» времени кадра — «текущее» время кадра).
Далее делаем таблицу сопряженности «широта — долгота» (напомню, что значения широты и долготы были ранее преобразованы из непрерывных в дискретные путем округления до одной десятой). И «разворачиваем» таблицу сопряженности в dataframe из 3 колонок: широта, долгота, частота (количество твитов в данной точке). Убираем строки, в которых частота равна нулю или координаты выходят за установленные границы.
Преобразование широты и долготы в числовые переменные необходимо потому, что после «сворачивания-разворачивания» данных они преобразуются в категориальные (factor в терминологии R).
Осталось посчитать цвета точек. Для этого в предварительном цикле вычисляется максимальный возможный объем твитов в одной точке за весь будущий «фильм». Он берется за максимум (max.color), а относительно него рассчитываются цвета для всех остальных точек (логарифмирование — чтобы «выровнять» шкалу):
...
if(nrow(frame.twits)>0){
p <- p + geom_point(aes(frame.twits$Long,frame.twits$Lat, size=frame.twits$Volume * 5),
colour=twits.colors[frame.colors], alpha = .75)
}
...
Вроде бы все, можно сохранять изображение и закрывать цикл, но для очередного «оживления картинки» я решил добавить несколько реальных сообщений в кадр. Для этого из общего массива случайно выбрал несколько десятков твитов, для них собрал тексты сообщений и создал еще один dataframe — время публикации, текст твита, «время жизни», «время появления», «время исчезновения», цвет, координаты, размер и прозрачность. Время жизни, координаты, цвет и размер генерируются при инициализации скрипта со случайными отклонениями от «оптимальных» значений:
twit.texts$x <- rnorm(nrow(twit.texts), mean = 100, sd = 30)
twit.texts$y <- rnorm(nrow(twit.texts), mean = 56, sd = 15)
twit.texts$size <- rnorm(nrow(twit.texts), mean = 10, sd = 2)
Вывод в кадр контролируется с помощью прозрачности: если «текущее» время кадра не попадает во «время жизни» твита, его «непрозрачность» (opacity) равна нулю. Если в текущем времени твит «существует» — его непрозрачность рассчитывается в зависимости от близости к центру жизненного периода. Получается, что твит «проявляется» и плавно исчезает. В коде это выглядит следующим образом:
Длина f.name «нулями» подгоняется таким образом, чтобы все имена «подходили» под одну маску по количеству символов.
Собираем видео
Для сборки итогового ролика использовался ffmpeg: ffmpeg -f image2 -i img%04d.png -q:v 0 -vcodec mpeg4 -r 24 happynewyear.mp4
Однако не все так просто. Видео целиком не собирается — у .png файлов, получаемых от ggplot2, разная глубина цвета. Возможно, эту проблему можно было решить каким-то более правильным способом, но я воспользовался Python Imaging Library:
import os
from PIL import Image
path = u'/path/to/frames/'
dirList=os.listdir(path)
for filename in dirList:
if filename[-3:] == 'png':
im = Image.open(path + filename).convert('RGB')
im.save(path + filename)
Теперь все кадры собираются в один ролик. Видео готово, можно грузить на YouTube. Добавляем пару YouTube-эффектов (ведь если ружье висит на стене, из него надо время от времени постреливать).
Финал:
В данном тексте я описал не все части R-скрипта, а часть цитат из кода скомпонована по принципу решаемой задачи, а не по логике работы. Поэтому в приложении выкладываю ссылку на полный код с незначительным количеством комментариев: pastebin.com
Возможные варианты развития
Добавить дату, т.к. 12-часовой циферблат не слишком информативен, когда требуется визуализировать временной интервал в несколько суток.
Добавить полоску с гистограммой или чем-то вроде графика плотности вероятности по общему объему данных в каждый момент времени.
Вопросы к сообществу
Существует ли для R библиотека, сопоставимая по простоте с maps, но с более актуальной информацией по современной геополитике? Без USSR, Yugoslavia и Czechoslovakia?
Как можно попробовать оптимизировать вычисление цветов палитры точек, чтобы не «прогонять» предварительно весь цикл «вхолостую»?
Можно ли «побороть» ggplot2 или ffmpeg, чтобы не требовалось дополнительной перекодировки цветности кадров (исключить PIL из процесса)?
И вообще — выслушаю другие указания на собственную гуманитарную криворукость и возможности оптимизации.
 АДМИНКА
АДМИНКА НАВИГАЦИЯ
НАВИГАЦИЯ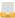 СВЯЗЬ С НАМИ
СВЯЗЬ С НАМИ РАДИО
РАДИО
 ЛУЧШИЕ ЧАТЫ
ЛУЧШИЕ ЧАТЫ
 СЧЁТЧИКИ
СЧЁТЧИКИ