 АДМИНКА
АДМИНКА НАВИГАЦИЯ
НАВИГАЦИЯ СВЯЗЬ С НАМИ
СВЯЗЬ С НАМИ РАДИО
РАДИО«MilkyWeb — Graph of Everything»
Раздел: Социальные сети
 В данной статье я хочу поделиться своими мыслями по поводу способов решения фундаментальных проблем современного Интернета. Хочу описать модель, которая, по моему мнению, может помочь ещё лучше упорядочить знания в интернете, и продемонстрировать свою попытку реализации такой модели. IntroСоциальные сети и поисковые машины пытаются упорядочить как можно больше информации об окружающем мире и в частности о пользователе.В компьютерных науках базисом для описания любой предметной области (ПО) являются онтологии или их упрощённая разновидность – графы. Именно с их помощью возможно наиболее однозначно для компьютера описать любую базу знаний. В существующем веб-пространстве создано большое количество специализированных графов: Facebook, Linkedin, Foursquare и т.д. Как известно Google расширяет свой Knowledge Graph и активно использует его в поисковых механизмах. Проблема в том, что в мире бесконечное количество предметных областей и чтобы создать новый граф принято создавать новую социальную сеть. Проект MilkyWeb (MW, МилкиВэб), который я хочу презентовать – это попытка создать универсальный инструмент для описания любых предметных областей (создания любых графов) в одном месте. Другими словами, это попытка создать универсальную Проект ещё не вышел из стадии альфа, поэтому интерфейс оставляет желать лучшего, за что прошу не серчать. Сайт верстался, только под Chrome. На поддержку кросс-браузерности решил время пока не тратить, поэтому приношу извинения пользователям других браузеров. Идеология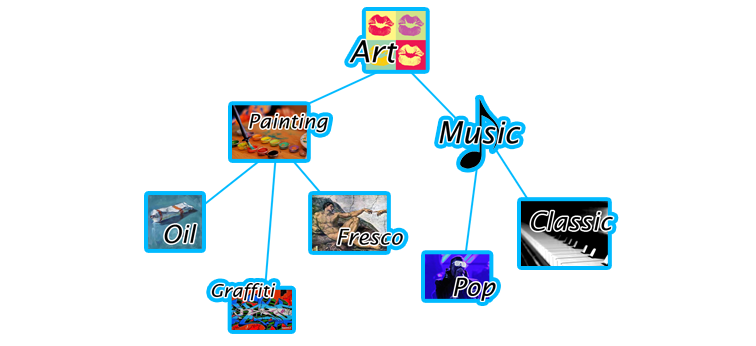 В основе идеологии проекта лежит модель онтологии – математического представления знаний. Она базируется на трёх китах: концептах, индивидах и предикатах. Концепты – это абстрактные понятия окружающего мира. Грубо говоря, это обобщённые (собирательные) наименования вещей и явлений, которые нас окружают. Множество концептов образуют иерархию, например, понятие «Программист» производное от понятия «Человек», а последнее в свою очередь является «Организмом». Можно провести аналогию с программированием: Концепты в онтологии – это классы в ООП. Концепты бывают двух видов: абстрактные понятия и множества (или Анцесторы от англ. Ancestor – предок, прародитель). Понятие «дружба» абстрактно, в то время как «машина» – это название множества реальных объектов. Индивиды – объекты, которые окружают нас в реальном мире. Каждый индивид является реализацией хотя бы одного концепта-анцестора. В контексте ООП – индивиды концептов – это экземпляры классов. Например: объект «Альберт Эйнштейн» – это индивид концепта «Учёный». Наследование, естественно, поддерживается. Так как «Учёный» – это «Человек», то «Альберт Эйнштейн» тоже является «Человеком». Когда новый пользователь создаёт аккаунт в MW, фактически это означает создание нового индивида концепта «Человек» в онтологии. В терминах графов концепты и индивиды являются вершинами графа, в то время как рёбрами (или дугами) выступают предикаты. Предикаты – это свойства, с помощью которых вершины графа связаны между собой. Простой пример предиката, как многие смогли догадаться, это отношение дружбы в FB или ВК. 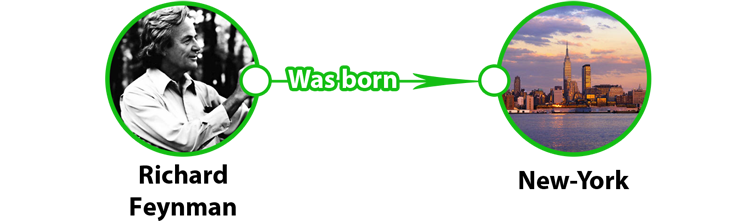 Изображённая на рисунке выше связь называется триплетом, т.к. в ней участвуют три составляющих: субъект «Richard Feynman» (вершина графа), предикат «Родился» (дуга графа), объект «New-York» (вершина графа). По сути, вся задача проекта МилкиВеб сводится к тому, чтобы пользователь смог создать страницу любого объекта окружающего мира (концепта или индивида) и смог семантически правильно связать её с другими страницами (с помощью предиката). Каждый предикат создаётся в связке с одним или несколькими концептами. Например, свойства «друг» или «мама» могут быть только у индивидов концепта «человек»; а предикат «CEO» может связывать «человека» и «компанию». Предикаты бывают литеральными. Такие предикаты-«литералы» указывают не на вершину графа, а на какое-либо значение. Каждый литерал имеет тип, например: строка, целое число, дата, географические координаты и т.д. (в данный момент поддерживаются только URL-литералы). Концепты и предикаты являются каркасом любой онтологии, то есть шаблоном, на котором строится весь граф, поэтому на данный момент эти сущности могут быть созданы только администрацией сайта. Этот процесс включает не только создание сущностей как таковых, но их настройку, которую пользователь не видит. Например, каждый предикат имеет порог на максимальное количество триплетов. Так с предикатом «мама» у индивида может быть только один триплет, а с предикатом «друг» – множество. ПримерКак я сказал, администрация создаёт каркас онтологии, а пользователи наполняют её. Приведу пример наполнения предметной области на основе концепта «фильм». Администратор создаёт концепт «фильм», и набор необходимых предикат таких как «в ролях», «режиссёр», «продюсер», «премьера», «страна», «любимый фильм», «смотрю». Пользователь FOO на основе концепта «фильм» создаёт страницу (индивид) «Пираты Карибского моря» и начинает её “описывать”. С помощью предиката «в ролях» он указывает, что в фильме снимались индивиды «Джонни Депп» и «Кира Найтли». Затем он связывает страницу с продюсером, режиссером и страной. Литералом «премьера» пользователь указывает, что премьера фильма состоялась 28 июня 2003 года. Окей, основные данные о фильме были внесены, но что дальше? Дальше FOO может указать, что «Пираты Карибского моря» – это его «любимый фильм». В это время пользователь GOO, который приходится другом FOO, как раз скучал за монитором и увидел в своей ленте только что созданный FOO триплет. Он воспринял это как призыв к действию и решил Я не зря выбрал предметную область «фильмы» для примера. Инженеры фейсбука как раз работают над тем, чтобы структурировать такие мгновения из жизни людей. Подробнее: www.wired.com/business/2012/11/mike-vernal-facebook/ Хочу также отметить, что предикат «любимый фильм» и кнопка «I like» на странице фильма на сайте IMDB – это не одно и то же. Семантика лайков очень размыта и не позволяет однозначно сказать, что же имел в виду пользователь, когда “лайкал” ту или иную страницу. Такая структура сильно упрощает описание той или иной предметной области. Если в Фейсбуке есть константный набор шаблонов для создания страниц, то в вышеописанной системе шаблоны можно создавать налету. Если в один момент времени мы решим привнести в социальную сеть новую ПО, необходимо будет просто создать набор концептов и предикатов, характерных для данной сферы. В данный момент все создаваемые страницы поддерживают только английский язык (стоит учитывать при поиске). В планах сделать механизм локализации на другие языки. Data sharing и проблемы Big DataЯ не нашёл подходящего устоявшегося в русском языке выражения, обозначающего sharing в понимании “делиться информацией” или “распространять информацию”, поэтому термин в заголовке оставил без перевода.В последнее время для описания области, которой характерен бурный рост количества информации, принято использовать понятие Big Data. Априори под этим термином подразумевается проблема: темп генерации данных настолько велик, что наиболее ценная информация может затеряться в общем потоке. Чтобы информация не терялась, необходимо её структурировать и классифицировать. Как показала практика, формирование news-feed’а на основе постов “от друзей” не самый лучший вариант. Точнее, такой способ хорош для того чтобы получать информацию об окружающих тебя людях, но не об интересующих вещах в общем. Как следствие, во Вконтакте новостная лента завалена котиками и цитатами “великих” людей. Можно пробовать подписываться на тематические паблики, но это не гарантирует доставку в пользовательский фид всей генерируемой в данный момент времени информации, которая могла бы быть интересна юзеру. Фейсбук лепит костыль за костылём, чтобы доставить только самую релевантную информацию в ленту пользователю. И в какой-то степени этого достаточно, но алгоритм построения ньюс-фида основан на действиях пользователя (анализ лайков, комментариев и т.д.), поэтому это также не является универсальным. На мой взгляд, наиболее успешно приблизиться к модели «пришёл, узнал всё актуальное, ушёл» получилось у Твиттера и Hacker News. Поэтому механику распространения информации в MilkyWeb я изначально пытался сделать чем-то средним между T и HN. Т.е. пользователь заходит на сайт и получает всю информацию, которая его могла бы заинтересовать за последнее время X. Но не только со страниц, на которые он подписан (Твиттер, FB, VK), но и по тематическим стримам (HN). В MW распространять можно текст (до 2000 знаков), ссылки и видео (YouTube). Фотографии пока что нет – их дорого хранить. Как пользователь может делиться информацией и кто эту информацию получит?Пользователь может:
Два последних способа – это то, что касается попытки решения проблемы Big Data. Основная идея такая: Пользователь X имеет информацию, которая тематически относится к той или иной сфере реальной жизни. Он не задумывается над тем, куда эту информацию запостить, а просто кидает её в общий тематический стрим для той или иной ПО. И теперь задача системы – на основе действий других пользователей (например, ранжирование или репосты) выделить наиболее ценные данные из общего потока. Работа над этим механизмом ещё ведётся. Системы ранжирования контента ещё нет, но она будет реализована в ближайшее время, и есть идеи как на основе всего этого сделать пользовательский новостной поток релевантнее, чем в других сетях. Именно модель, описанная в предыдущей главе, позволяет семантически однозначно различать понятия и правильно классифицировать информацию. Естественно, такой подход может порождать волны спама. В данный момент на сайте нельзя постить больше одного сообщения в 20 сек. В будущем буду более разумно решать эту проблему. Сейчас задача в том, чтобы проверить механику на жизнеспособность и как раз выделить возможные критические моменты. Как читатель, наверное, догадался, в такой системе есть большой потенциал для распространения таргетированного контента. Можно делать сложные выборки для выбора целевой аудитории. Например, отправить сообщение всем, кто «Программист» и «живёт в» «Москва»; или тем, кто «купил» «айФон» и «купил» «айПад»; или всем, кто «водит» «мерседес». Возможно, когда-нибудь это станет способом монетизации, но сейчас миссия проекта МилкиВеб в другом. О ней я и хочу рассказать в следующей главе. Семантическая паутинаСемантическая паутина (СП) – это веб-пространство, в котором контент, генерируемый человеком, понятен для компьютера.Этого можно достичь путём добавления метаданных в веб-документ (например, html). Метаданные широко используются в сети и выполняют важные роли при поиске, структурировании данных и т.д. Но для того, чтобы поисковая машина смогла “понять” содержание той или иной страницы, необходимо, чтобы эта страница сопровождалась отдельным документом с понятным для компьютера описанием (в виде графа) той части мира, о которой идёт речь на исходной странице. Спецификация требует, чтобы такие мета-документы были составлены в формате RDF. Проблема в том, что эти файлы должны кем-то создаваться, чтобы затем быть прикреплёнными к html-документу. Собственно, это та проблема, за решение которой я взялся два года назад в виде дипломной работы. Цель была – сделать удобный и интерактивный инструмент для создания RDF-описаний, централизованное хранилище мета-данных, где они будут накапливаться и не будут дублироваться. Со временем я немного отклонился от заданного направления в пользу социального аспекта. Но уже сейчас возможно получить RDF-описание той или иной сущности перейдя по адресу alpha.milkyweb.net/rdf/{ c | p | i }/id_сущности. Например, RDF-документы индивида «Moscow» и концепта «Human» лежат по адресам alpha.milkyweb.net/rdf/i/10460 и alpha.milkyweb.net/rdf/c/10000 соответственно (пользовательская информация естественно не публична). То есть всё, что остаётся веб-мастеру – это просто прикрепить ссылку на необходимый объект к веб-странице своего сайта. В будущем поисковая машина заберёт документ по указанному урлу и сможет классифицировать контент на странице, увеличивая релевантность поисковой выдачи. Или же можно будет в реальном времени наблюдать появление контента для той или иной сущности во всем Интернете. Согласитесь, круто же! :) Для специалистов в этой сфере отмечу, что интеграция с существующими словарями планируется. Конечно, я всё сильно упрощаю. Для того чтобы популяризовать СП, одной социальной сетью не обойдёшься. Скорее всего, необходимо создавать специальные фреймворки для веб-разработчиков, которые автоматизируют процесс пометки контента метаданными. Но я верю, что рано или поздно такой механизм будет работать, и первый шаг в эту сторону – это создание глобальной базы знаний интернета. ПроблемыСамые большие проблемы, с которыми я столкнулся, лежат в идеологи проекта и в терминологии онтологий как таковых.Все спецификации технологий СП (RDF, OWL) от W3C утверждают, что для описания веб-онтологий можно обойтись Концептами, Индивидами и Предикатами, и я поверил этому на некоторое время. В русской википедии можно найти такое описание понятия «Концепт»: Понятия (concepts) — абстрактные группы, коллекции или наборы объектов. Они могут включать в себя экземпляры, другие классы, либо же сочетания и того, и другого. И дальше идёт пример с небольшим отступлением: Понятие «люди», вложенное понятие «человек». Чем является «человек» — вложенным понятием, или экземпляром (индивидом) — зависит от онтологии. Неприметное с первого взгляда замечание (выделено курсивом) является фундаментальной проблемой философов всех времен. Если мы начнём создавать глобальную онтологию по этим “классическим правилам”, вся наша структура тут же рухнет, в чём я убедился лично. Изначально я считал, что концепты в моей сети – это абстрактные понятия, которые могут или не могут “иметь” индивидов. А индивиды в свою очередь – это реальные объекты, которые можно пощупать руками и которые “реализуют” какие-то концепты. Но предположим, что у нас есть концепт «Телефон». Теперь нам необходимо создать страницу айФона. Но что такое «айФон»: концепт или индивид? Предположим, что это индивид. И в какой-то момент времени юзер FOO решает создать персональную страницу того девайса «айФон», который лежит у него в кармане. Зачем? Неважно, возможно, он хочет выставить его на продажу. Важно здесь то, что если «айФон» – это индивид, то уже нельзя создать страницу конкретного девайса, т.к. мы ограничили уровень абстракции и система перестаёт быть целостной. Окей, предположим что «айФон» – это концепт. Но мы изначально решили, что концепты – это фундаментальные понятия, они не могут приходить и уходить со временем. То есть не будем же мы для каждого нового продукта, созданного человечеством, создавать отдельный концепт в иерархии. Поэтому сама идея о том, что в мире существуют концепты и индивиды, верна только в заранее установленных рамках и такой подход не может быть использован для создания глобальной онтологии. Таких подводных камней огромное множество, и я думаю, что создать универсальный способ описания мира можно только путём проверок и перестановок. OutroЯ не жду от проекта быстрой отдачи, как я и сказал ранее – на данный момент это эксперимент.Много вопросов и проблем стоят ребром. Возможно, глобальный граф вообще не имеет место быть. Или, возможно, предложенный подход просто негоден для его создания. Цель моей деятельности – практическим путём найти возможные способы решения фундаментальных проблем глобальной паутины. Всё, что я описал выше – это лишь верхушка айсберга моих наработок и идей. Если тема окажется актуальна, постараюсь продолжить цикл статей. Буду приблагодарен за фидбэк любого содержания! Можете писать в комментариях, в личку или в форму на сайте (о багах и хаках постить туда же). Если кому-то изложенные идеи покажутся интересными, и этот кто-то захочет принять участие в развитии проекта – я открыт к сотрудничеству (ядро сайта – Java + MySQL). Под развитием я понимаю не только разработку, но и наполнение базы знаний. Сейчас в сети создано около 1000 сущностей в разных предметных областях, что, конечно же, очень мало. Если вы не нашли страницу своего города, страны, любимой музыкальной группы, фильма и т.д., попробуйте создать такую страницу и поделитесь вашим user-experience. PS: Те, кто запросил приглашение, не удивляйтесь, если оно придёт не сразу. SMTP сервер – это наш bottleneck. Можете написать мне в личку – кину. Благодарю за внимание! |
 ЛУЧШИЕ ЧАТЫ
ЛУЧШИЕ ЧАТЫ
 СЧЁТЧИКИ
СЧЁТЧИКИ